A karakterlánc konvertálása bájt tömbre és visszafordítás Java-ban
1. Bemutatkozás
Gyakran kell konvertálnunk a következők között Húr és byte tömb Java-ban. Ebben az oktatóanyagban részletesen megvizsgáljuk ezeket a műveleteket.
Először megvizsgáljuk a Húr a byte sor. Ezután megfordítjuk a hasonló műveleteket.
2. Konvertálás Húr nak nek Byte Sor
A Húr Unicode karakter tömbként van tárolva a Java-ban. Átalakítani a byte tömb, a Karakterek sorozatát bájtsorrendbe fordítjuk. Ehhez a fordításhoz példányát használjuk Charset. Ez az osztály hozzárendelést ad meg a chars és ezek sorrendje bytes.
A fenti folyamatra úgy hivatkozunk kódolás.
Kódolhatjuk a Húr ba be byte tömb Java-ban többféle módon. Nézzük meg részletesen mindegyiket példákkal.
2.1. Használata String.getBytes ()
A Húr osztály három túlterheltet biztosít getBytes kódolási módszerek a Húr -ba egy bájt sor:
- getBytes () - kódol a platform alapértelmezett karakterkészletével
- getBytes (String charsetName) - kódol a megnevezett karakterkészlet segítségével
- getBytes (karakterkészlet-karakterkészlet) - kódol a mellékelt karakterkészlet segítségével
Először, kódoljunk egy karakterláncot a platform alapértelmezett karakterkészletével:
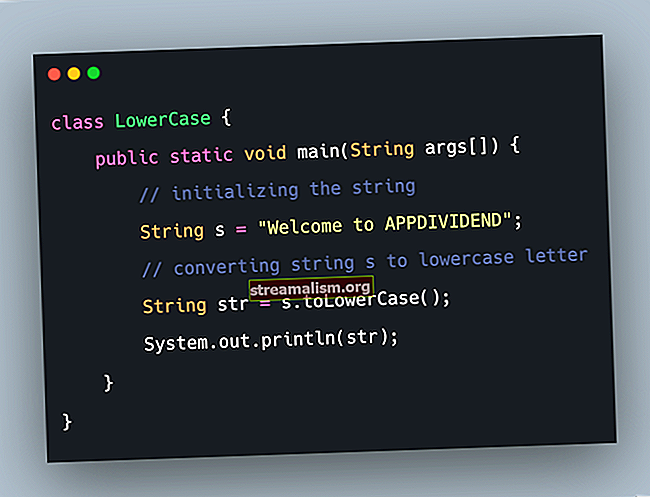
String inputString = "Helló világ!"; byte [] byteArrray = inputString.getBytes ();A fenti módszer platformfüggő, mivel a platform alapértelmezett karakterkészletét használja. Hívással megszerezhetjük ezt a karakterkészletet Charset.defaultCharset ().
Másodszor, kódoljunk egy karakterláncot egy megnevezett karakterkészlet használatával:
@Test public void, amikorGetBytesWithNamedCharset_thenOK () dobja az UnsupportedEncodingException {String inputString = "Hello World!"; String charsetName = "IBM01140"; byte [] byteArrray = inputString.getBytes ("IBM01140"); assertArrayEquals (új bájt [] {-56, -123, -109, -109, -106, 64, -26, -106, -103, -109, -124, 90}, byteArrray); }Ez a módszer dob UnsupportedEncodingException ha a megnevezett karakterkészlet nem támogatott.
A fenti két verzió viselkedése nincs meghatározva, ha a bemenet olyan karaktereket tartalmaz, amelyeket a karakterkészlet nem támogat. Ezzel szemben a harmadik verzió a karakterkészlet alapértelmezett helyettesítő bájt tömbjét használja a nem támogatott bemenet kódolásához.
Következő, hívjuk a harmadik verzióját a getBytes () metódus és adja át a Karakterkészlet:
@Test public void whenGetBytesWithCharset_thenOK () {String inputString = "Hello ਸੰਸਾਰ!"; Charset charset = Charset.forName ("ASCII"); byte [] byteArrray = inputString.getBytes (karakterkészlet); assertArrayEquals (új bájt [] {72, 101, 108, 108, 111, 32, 63, 63, 63, 63, 63, 33}, byteArrray); }Itt a gyári módszert alkalmazzuk Charset.forName hogy a Charset. Ez a módszer futásidejű kivételt dob, ha a kért karakterkészlet neve érvénytelen. Futásidejű kivételt is dob, ha a karakterkészlet támogatott a jelenlegi JVM-ben.
Néhány karakterkészlet azonban garantáltan elérhető lesz minden Java platformon. A StandardCharsets osztály meghatározza ezeknek az karaktereknek az állandóit.
Végül, kódoljuk az egyik szabványos karakterkészlet használatával:
@Test public void whenGetBytesWithStandardCharset_thenOK () {String inputString = "Hello World!"; Karakterkészlet = standardCharsets.UTF_16; byte [] byteArrray = inputString.getBytes (karakterkészlet); assertArrayEquals (új bájt [] {-2, -1, 0, 72, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 87, 0, 111, 0, 114, 0 , 108, 0, 100, 0, 33}, byteArrray); }Így befejezzük a különféle áttekintését getBytes változatok. Ezután vizsgáljuk meg a Charset maga.
2.2. Használata Charset.encode ()
A Charset osztály biztosítja kódol(), egy kényelmes módszer, amely az Unicode karaktereket bájtokká kódolja. Ez a módszer mindig az érvénytelen beviteli és a leképezhetetlen karaktereket helyettesíti a karakterkészlet alapértelmezett helyettesítő bájt tömbjével.
Használjuk a kódol módszer a Húr ba be byte sor:
@Test public void whenEncodeWithCharset_thenOK () {String inputString = "Hello ਸੰਸਾਰ!"; Karakterkészlet = standardCharsets.US_ASCII; byte [] byteArrray = charset.encode (inputString) .array (); assertArrayEquals (új bájt [] {72, 101, 108, 108, 111, 32, 63, 63, 63, 63, 63, 33}, byteArrray); }Mint fent láthatjuk, a nem támogatott karaktereket lecserélték a karakterkészlet alapértelmezett helyettesítésére byte 63.
Az eddig alkalmazott megközelítések a CharsetEncoder osztályon belül a kódolás elvégzéséhez. Vizsgáljuk meg ezt az osztályt a következő szakaszban.
2.3. CharsetEncoder
CharsetEncoder átalakítja az Unicode karaktereket egy adott karakterkészlet bájtsorozatává. Ezenkívül finom részletgazdagságot biztosít a kódolási folyamat felett.
Használjuk ezt az osztályt a Húr ba be byte sor:
@Test public void, amikor aUsingCharsetEncoder_thenOK () dobja a CharacterCodingException {String inputString = "Hello ਸੰਸਾਰ!"; CharsetEncoder encoder = StandardCharsets.US_ASCII.newEncoder (); encoder.onMalformedInput (CodingErrorAction.IGNORE) .onUnmappableCharacter (CodingErrorAction.REPLACE) .replaceWith (új byte [] {0}); byte [] byteArrray = kódoló.encode (CharBuffer.wrap (inputString)) .array (); assertArrayEquals (új byte [] {72, 101, 108, 108, 111, 32, 0, 0, 0, 0, 0, 33}, byteArrray); }Itt létrehozunk egy példányt CharsetEncoder felhívásával a newEncoder módszer a Charset tárgy.
Ezután megadjuk a hibaállapotokra vonatkozó műveleteket a onMalformedInput () és onUnmappableCharacter () mód. A következő műveleteket adhatjuk meg:
- IGNORE - dobja el a hibás bevitelt
- KICSERÉLÉS - cserélje ki a hibás bemenetet
- JELENTÉS - jelentse a hibát a CoderResult tárgy vagy dobás a CharacterCodingException
Továbbá a Cseréld ki() módszer a csere megadására byte tömb.
Így befejezzük a különféle megközelítések áttekintését, hogy egy Stringet bájttömbbé alakítsunk. Most nézzük meg a fordított műveletet.
3. Bájtömb átalakítása karakterláncra
Utalunk a konvertálás folyamatára byte tömb a Húr mint dekódolás. A kódoláshoz hasonlóan ehhez a folyamathoz a Charset.
Azonban nem használhatunk egyetlen karakterkészletet sem a bájt tömb dekódolásához. Azt a karakterkészletet kell használnunk, amelyet a Húr ba,-be byte sor.
Sokféleképpen konvertálhatunk egy bájt tömböt String-be. Vizsgáljuk meg mindegyiket részletesen.
3.1. Használni a Húr Konstruktőr
A Húr osztályban kevés a kivitelező, amelyek a byte tömb bemenetként. Mind hasonlítanak a getBytes módszerrel, de fordítva működik.
Első, konvertáljunk egy bájt tömböt Húr a platform alapértelmezett karakterkészletének használata:
@Test public void whenStringConstructorWithDefaultCharset_thenOK () {byte [] byteArrray = {72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100, 33}; String string = új karakterlánc (byteArrray); assertNotNull (karakterlánc); }Vegye figyelembe, hogy itt nem állítunk semmit a dekódolt karakterlánc tartalmáról. Ennek oka lehet, hogy valami másra dekódolja, a platform alapértelmezett karakterkészletétől függően.
Ezért általában kerülnünk kell ezt a módszert.
Másodszor, használjunk egy megnevezett karakterkészletet a dekódoláshoz:
@Test public void, amikor aStringConstructorWithNamedCharset_thenOK () dobja az UnsupportedEncodingException {String charsetName = "IBM01140" parancsot; bájt [] byteArrray = {-56, -123, -109, -109, -106, 64, -26, -106, -103, -109, -124, 90}; String string = új karakterlánc (byteArrray, charsetName); assertEquals ("Hello World!", karakterlánc); }Ez a módszer kivételt hoz, ha a megnevezett karakterkészlet nem érhető el a JVM-en.
Harmadszor, használjuk a Charset objektum a dekódoláshoz:
@Test public void whenStringConstructorWithCharSet_thenOK () {Charset charset = Charset.forName ("UTF-8"); byte [] byteArrray = {72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100, 33}; String string = új karakterlánc (byteArrray, karakterkészlet); assertEquals ("Helló világ!", karakterlánc); }Végül, használjunk szabványt Charset ugyanazért:
@Test public void whenStringConstructorWithStandardCharSet_thenOK () {Charset charset = StandardCharsets.UTF_16; byte [] byteArrray = {-2, -1, 0, 72, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 87, 0, 111, 0, 114, 0, 108, 0, 100, 0, 33}; String string = új karakterlánc (byteArrray, karakterkészlet); assertEquals ("Helló világ!", karakterlánc); }Eddig a byte tömb a Húr a konstruktor segítségével. Vizsgáljuk meg most a többi megközelítést.
3.2. Használata Charset.decode ()
A Charset osztály biztosítja a dekódolni () módszer, amely átalakítja a ByteBuffer nak nek Húr:
@Test public void whenDecodeWithCharset_thenOK () {byte [] byteArrray = {72, 101, 108, 108, 111, 32, -10, 111, 114, 108, -63, 33}; Karakterkészlet = standardCharsets.US_ASCII; Karaktersorozat = charset.decode (ByteBuffer.wrap (byteArrray)) .toString (); assertEquals ("Hello orl !", karakterlánc); }Itt, az érvénytelen bemenetet helyettesíti a karakterkészlet alapértelmezett helyettesítő karakterével.
3.3. CharsetDecoder
A dekódolás belső megközelítésének összes korábbi megközelítése használja a CharsetDecoder osztály. Ezt az osztályt közvetlenül használhatjuk a dekódolási folyamat finomszemcsés ellenőrzésére:
@Test public void whenUsingCharsetDecoder_thenOK () dobja a CharacterCodingException {byte [] byteArrray = {72, 101, 108, 108, 111, 32, -10, 111, 114, 108, -63, 33}; CharsetDecoder dekóder = StandardCharsets.US_ASCII.newDecoder (); decoder.onMalformedInput (CodingErrorAction.REPLACE) .onUnmappableCharacter (CodingErrorAction.REPLACE) .replaceWith ("?"); Karaktersorozat = decoder.decode (ByteBuffer.wrap (byteArrray)) .toString (); assertEquals ("Hello? orl ?!", karakterlánc); }Itt az érvénytelen bemeneteket és a nem támogatott karaktereket „?” -Re cseréljük.
Ha tájékoztatni akarunk érvénytelen inputokról, akkor megváltoztathatjuk a dekóder mint:
decoder.onMalformedInput (CodingErrorAction.REPORT) .onUnmappableCharacter (CodingErrorAction.REPORT)4. Következtetés
Ebben a cikkben többféle konverziót vizsgáltunk Húr bájt tömbre, és fordítsa meg. Meg kell választanunk a megfelelő módszert a bemeneti adatok, valamint az érvénytelen bemenetekhez szükséges ellenőrzési szint alapján.
Szokás szerint a teljes forráskód megtalálható a GitHubon.