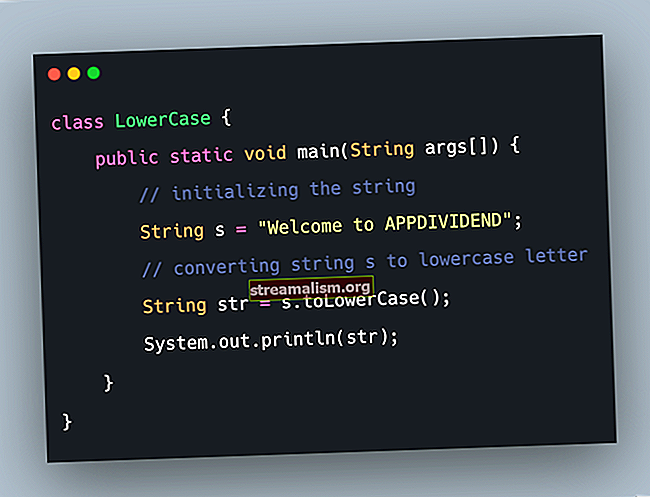
A Java HashMap a motorháztető alatt
1. Áttekintés
Ebben a cikkben megismerjük a legnépszerűbb megvalósítását Térkép felületet a Java Collections Framework-ről részletesebben, ott folytatjuk, ahol a bevezető cikkünk abbamaradt.
Mielőtt belekezdenénk a megvalósításba, fontos kiemelni, hogy az elsődleges Lista és Készlet a gyűjtőfelületek kibővülnek Gyűjtemény de Térkép nem.
Egyszerűen fogalmazva: HashMap kulcsok szerint tárolja az értékeket, és API-kat biztosít a tárolt adatok különféle módon történő hozzáadásához, visszakereséséhez és kezeléséhez. A megvalósítás az a hashtable elvei alapján, amely eleinte kissé összetettnek tűnik, de valójában nagyon könnyen érthető.
A kulcsérték-párokat az úgynevezett vödrök tárolják, amelyek együttesen alkotják az úgynevezett táblázatot, amely valójában egy belső tömb.
Miután megtudtuk a kulcsot, amely alatt egy objektumot tárolni vagy tárolni akarunk, a tárolási és visszakeresési műveletek állandó időben történnek, O (1) jól méretezett hash térképen.
Ahhoz, hogy megértsük, hogyan működnek a hash térképek a motorháztető alatt, meg kell értenünk a tároló és visszakeresési mechanizmust HashMap. Sokat fogunk ezekre koncentrálni.
Végül, HashMap kapcsolódó kérdések meglehetősen gyakoriak az interjúk során, tehát ez egy jó módja az interjú előkészítésének vagy az előkészítésnek.
2. A put () API
Ha egy értéket el akarunk tárolni egy kivonatkártyán, akkor a tedd API, amely két paramétert vesz fel; egy kulcs és a hozzá tartozó érték:
V put (K kulcs, V érték);Ha egy kulcs alatt hozzáadunk egy értéket a térképhez, akkor a hash kód() A kulcsobjektum API-ját hívják le úgynevezett kezdeti kivonatértéknek.
Ahhoz, hogy ezt működés közben lássuk, hozzunk létre egy objektumot, amely kulcsként fog működni. Csak egyetlen attribútumot hozunk létre, amelyet hash-kódként használunk a hash első szakaszának szimulálására:
nyilvános osztály MyKey {private int id; @Orride public int hashCode () {System.out.println ("HashCode () hívása"); visszatérési azonosító; } // kivitelező, beállítók és szerelők}Most már használhatjuk ezt az objektumot egy érték feltérképezésére a hash térképen:
@Test public void whenHashCodeIsCalledOnPut_thenCorrect () {MyKey kulcs = new MyKey (1); Térképtérkép = új HashMap (); map.put (kulcs, "val"); }A fenti kódban semmi nem történik, de figyeljen a konzol kimenetére. Valóban a hash kód metódust hívják meg:
HashCode () hívásaEzután a hash () A hash map API-t belsőleg hívják meg, hogy kiszámítsa a végső hash értéket a kezdeti hash érték felhasználásával.
Ez a végső kivonatérték végül a belső tömb indexéig vagy az úgynevezett vödör helyéig terjed.
A hash funkciója HashMap így néz ki:
statikus végső int hash (Object key) {int h; return (kulcs == null)? 0: (h = kulcs.hashCode ()) ^ (h >>> 16); }Amit itt meg kell jegyeznünk, az csak a kulcsobjektumból származó hash kód használata a végső hash érték kiszámításához.
Míg a tedd függvény, a végső hash értéket a következőképpen használják:
public V put (K kulcs, V érték) {return putVal (hash (kulcs), kulcs, érték, hamis, igaz); }Vegyük észre, hogy egy belső putVal függvényt hívják meg, és első paraméterként megadják neki a végső kivonatértéket.
Azon felmerülhet a kérdés, hogy miért használják újra a kulcsot ebben a függvényben, mivel a hash érték kiszámításához már használtuk.
Ennek oka az A hash maps mind a kulcsot, mind az értéket a tárolóhelyen tárolja a-ként Térkép. Belépés tárgy.
Amint azt korábban megbeszéltük, az összes Java-gyűjteményi keretrendszer-interfész kiterjed Gyűjtemény interfész de Térkép nem. Hasonlítsa össze a korábban látott Map felület deklarációját a Készlet felület:
nyilvános felület A szett kiterjeszti a GyűjteménytEnnek oka az A térképek nem pontosan tárolnak egyetlen elemet, mint más gyűjtemények, hanem a kulcs-érték párok gyűjteményét.
Tehát a Gyűjtemény interfész, például hozzá, array nincs értelme, amikor arról van szó Térkép.
Az a koncepció, amelyet az elmúlt három bekezdésben lefedtünk, a következők egyikét alkotja legnépszerűbb Java Collections Framework interjúk. Szóval érdemes megérteni.
A hash-térkép egyik speciális attribútuma, hogy elfogadja nulla értékek és nullkulcsok:
@Test public void givenNullKeyAndVal_whenAccepts_thenCorrect () {Map map = new HashMap (); map.put (null, null); }Ha egy nullkulccsal találkozunk a tedd művelethez automatikusan hozzárendeli a végső kivonatolási értéket 0, ami azt jelenti, hogy az alapul szolgáló tömb első elemévé válik.
Ez azt is jelenti, hogy ha a kulcs nulla, akkor nincs hash művelet, ezért a hash kód A kulcs API-ját nem hívják meg, így elkerülhető a null pointer kivétel.
A tedd művelet, amikor egy kulcsot használunk, amelyet korábban már használtunk egy érték tárolására, akkor a kulcshoz társított előző értéket adja vissza:
@Test public void givenExistingKey_whenPutReturnsPrevValue_thenCorrect () {Map map = new HashMap (); map.put ("kulcs1", "val1"); Karakterlánc rtnVal = map.put ("key1", "val2"); assertEquals ("val1", rtnVal); }különben visszatér nulla:
@Test public void givenNewKey_whenPutReturnsNull_thenCorrect () {Map map = new HashMap (); Karakterlánc rtnVal = map.put ("key1", "val1"); assertNull (rtnVal); }Mikor tedd null értéket ad vissza, ez azt is jelentheti, hogy a kulccsal társított korábbi érték null, nem feltétlenül új kulcs-érték leképezés:
@Test public void givenNullVal_whenPutReturnsNull_thenCorrect () {Map map = new HashMap (); Karakterlánc rtnVal = map.put ("key1", null); assertNull (rtnVal); }A tartalmazzaKey Az API felhasználható az ilyen forgatókönyvek megkülönböztetésére, amint azt a következő alfejezetben láthatjuk.
3. Az kap API
A hash térképen már tárolt objektum lekéréséhez ismernünk kell azt a kulcsot, amely alatt tárolták. Hívjuk a kap API és adja át neki a kulcsobjektumot:
@Test public void whenGetWorks_thenCorrect () {Map map = new HashMap (); map.put ("kulcs", "val"); Karakterlánc val = map.get ("kulcs"); assertEquals ("val", val); }Belsőleg ugyanaz a hash elv érvényesül. A hashCode () A kulcsobjektum API-ja meghívásra kerül a kezdeti hash érték megszerzéséhez:
@Test public void whenHashCodeIsCalledOnGet_thenCorrect () {MyKey kulcs = new MyKey (1); Térképtérkép = új HashMap (); map.put (kulcs, "val"); map.get (kulcs); }Ezúttal a hash kód API-ja A kulcsom kétszer hívják; egyszer azért tedd és egyszer kap:
HashCode () hívása hashCode ()Ezt az értéket a belső hívásával újrarajzolják hash () API a végső hash érték megszerzéséhez.
Amint azt az előző szakaszban láttuk, ez a végső kivonatérték végül egy vödör helyére vagy a belső tömb indexévé válik.
Az adott helyen tárolt értékobjektumot ezután lekérik és visszaadják a hívó funkciónak.
Ha a visszaadott érték nulla, ez azt jelentheti, hogy a kulcsobjektum nincs társítva a hash map egyik értékével:
@Test public void givenUnmappedKey_whenGetReturnsNull_thenCorrect () {Map map = new HashMap (); Karakterlánc rtnVal = map.get ("key1"); assertNull (rtnVal); }Vagy egyszerűen azt jelentheti, hogy a kulcs kifejezetten egy null példányhoz lett hozzárendelve:
@Test public void givenNullVal_whenRetrieves_thenCorrect () {Map map = new HashMap (); map.put ("kulcs", null); Karakterlánc val = map.get ("kulcs"); assertNull (val); }A két forgatókönyv megkülönböztetéséhez használhatjuk a tartalmazzaKey API, amelyhez átadjuk a kulcsot, és csak akkor tér vissza igazra, ha a hash térképen létrehoztunk egy leképezést a megadott kulcshoz:
@Test public void whenContainsDistinguishesNullValues_thenCorrect () {Map map = new HashMap (); Karakterlánc val1 = map.get ("kulcs"); logikai valPresent = map.containsKey ("kulcs"); assertNull (val1); assertFalse (valPresent); map.put ("kulcs", null); Karakterlánc val = map.get ("kulcs"); valPresent = map.containsKey ("kulcs"); assertNull (val); assertTrue (valPresent); }A fenti teszt mindkét esetben a kap Az API hívás semleges, de meg tudjuk különböztetni, melyik melyik.
4. Gyűjtemény nézetek HashMap
HashMap három nézetet kínál, amelyek lehetővé teszik számunkra, hogy kulcsait és értékeit egy másik gyűjteményként kezeljük. Megszerezhetjük az összeset a térkép gombjai:
@Test public void givenHashMap_whenRetrievesKeyset_thenCorrect () {Map map = new HashMap (); map.put ("név", "baeldung"); map.put ("típus", "blog"); Set keys = map.keySet (); assertEquals (2, keys.size ()); assertTrue (keys.contains ("név")); assertTrue (keys.contains ("type")); }A készlet mögött maga a térkép áll. Így a készleten történt bármilyen változás a térképen is megjelenik:
@Test public void givenKeySet_whenChangeReflectsInMap_thenCorrect () {Map map = new HashMap (); map.put ("név", "baeldung"); map.put ("típus", "blog"); assertEquals (2, map.size ()); Set keys = map.keySet (); kulcsok.remove ("név"); assertEquals (1, map.size ()); }Megszerezhetjük a az értékek gyűjteményes nézete:
@Test public void givenHashMap_whenRetrievesValues_thenCorrect () {Map map = new HashMap (); map.put ("név", "baeldung"); map.put ("típus", "blog"); Gyűjtemény értékei = map.values (); assertEquals (2, értékek.méret ()); assertTrue (értékek.tartalmaz ("baeldung")); assertTrue (értékek.tartalmaz ("blog")); }Csakúgy, mint bármelyik kulcskészlet A gyűjteményben végrehajtott változtatások az alapul szolgáló térképen is megjelennek.
Végül megszerezhetjük a állítsa be az összes bejegyzés nézetét a térképen:
@Test public void givenHashMap_whenRetrievesEntries_thenCorrect () {Map map = new HashMap (); map.put ("név", "baeldung"); map.put ("típus", "blog"); Készlet bejegyzések = map.entrySet (); assertEquals (2, bejegyzések.méret ()); for (e bejegyzés: bejegyzések)} Ne feledje, hogy a hash térkép kifejezetten rendezetlen elemeket tartalmaz, ezért bármilyen sorrendet feltételezünk, amikor teszteljük a kulcsok és a bejegyzések értékeit a az egyes hurok.
Sokszor a gyűjtemény nézeteit ciklusban fogja használni, mint az utolsó példában, és pontosabban az iterátorokat használja.
Csak ne feledje, hogy a az összes fenti nézet iterátora kudarc.
Ha bármilyen strukturális módosítást végeznek a térképen, az iterátor létrehozása után egyidejű módosítás kivételt dob:
@Test (várható = ConcurrentModificationException.class) public void givenIterator_whenFailsFastOnModification_thenCorrect () {Map map = new HashMap (); map.put ("név", "baeldung"); map.put ("típus", "blog"); Set keys = map.keySet (); Iterátor it = kulcsok.iterátor (); map.remove ("type"); while (it.hasNext ()) {String kulcs = it.next (); }}Az egyetlen megengedett szerkezeti módosítás a eltávolítani magában az iterátoron végrehajtott művelet:
public void givenIterator_whenRemoveWorks_thenCorrect () {Térképtérkép = új HashMap (); map.put ("név", "baeldung"); map.put ("típus", "blog"); Set keys = map.keySet (); Iterátor it = kulcsok.iterátor (); while (it.hasNext ()) {it.next (); it.remove (); } assertEquals (0, map.size ()); }Az utolsó dolog, amelyre emlékezni kell ezekről a gyűjteménynézetekről: az iterációk teljesítménye. Itt a hash térkép meglehetősen gyengén teljesít, összehasonlítva a társaival összekapcsolt hash térkép és fa térképpel.
A hash-térkép fölötti ismétlés a legrosszabb esetben is megtörténik Tovább) ahol n a kapacitása és a bejegyzések száma összege.
5. HashMap teljesítmény
A hash térkép teljesítményét két paraméter befolyásolja: Kezdeti kapacitás és Terhelési tényező. A kapacitás a csoportok száma vagy az alapul szolgáló tömb hossza, a kezdeti kapacitás pedig egyszerűen a kapacitás a létrehozás során.
Röviden: a terhelési tényező vagy az LF annak mértéke, hogy a hash-térkép mennyire legyen teljes, miután néhány értéket hozzáad, mielőtt átméreteznék.
Az alapértelmezett kezdeti kapacitás 16 és az alapértelmezett terhelési tényező 0.75. Készíthetünk hash térképet a kezdeti kapacitás és az LF egyéni értékeivel:
Map hashMapWithCapacity = új HashMap (32); Map hashMapWithCapacityAndLF = új HashMap (32, 0,5f);A Java csapat által beállított alapértelmezett értékek a legtöbb esetben jól vannak optimalizálva. Ha azonban saját értékeit kell használnia, ami nagyon rendben van, akkor meg kell értenie a teljesítményre vonatkozó következményeket, hogy tudja, mit csinál.
Ha a hash map bejegyzések száma meghaladja az LF és a kapacitás szorzatát, akkor újrakezdve fordul elő i.e. egy másik belső tömb jön létre az eredetinek kétszer akkorával, és az összes bejegyzést áthelyezzük az új tömb új sávhelyeire.
A alacsony kezdeti kapacitás csökkenti a helyköltséget, de növeli az újrakezdés gyakoriságát. Az újrakezdés nyilvánvalóan nagyon drága folyamat. Tehát általában, ha sok bejegyzésre számít, akkor jelentősen magas kezdeti kapacitást kell beállítania.
A túloldalon, ha túl magasra állítja a kezdeti kapacitást, akkor iterációs idő alatt kell megfizetnie a költségeket. Amint azt az előző szakaszban láttuk.
Így a magas kezdeti kapacitás sok bejegyzéshez jó, kevés vagy egyáltalán nem iterálva.
A Az alacsony kezdeti kapacitás kevés bejegyzéshez jó, sok iterációval.
6. Ütközések a HashMap
Ütközés, pontosabban egy hash-kód ütközés a HashMap, olyan helyzet, amikor két vagy több kulcsobjektum ugyanazt a végső kivonatértéket adja és ennélfogva ugyanarra a tárolóhelyre vagy tömbindexre mutat.
Ez a forgatókönyv azért fordulhat elő, mert a egyenlő és hash kód szerződés, két egyenlőtlen objektum a Java-ban azonos hash-kóddal rendelkezhet.
Megtörténhet az alapul szolgáló tömb véges mérete miatt is, vagyis az átméretezés előtt. Minél kisebb ez a tömb, annál nagyobb az ütközés esélye.
Ennek ellenére érdemes megemlíteni, hogy a Java kivonatkód ütközés-feloldási technikát valósít meg, amelyet egy példával láthatunk.
Ne feledje, hogy a kulcs kivonatértéke határozza meg az objektum tárolására szolgáló sávot. Ha tehát bármely két kulcs kivonatkódja összeütközik, a bejegyzéseiket továbbra is ugyanazon a vödörben tárolják.
Alapértelmezés szerint a megvalósítás összekapcsolt listát használ a csoportos megvalósításként.
A kezdetben állandó idő O (1)tedd és kap a műveletek lineáris időben fognak bekövetkezni Tovább) ütközés esetén. Ez azért van, mert miután megtalálta a vödör helyét a végső kivonatértékkel, az ezen a helyen található kulcsokat összehasonlítjuk a megadott kulcsobjektummal egyenlő API.
Ennek az ütközésfeloldási technikának a szimulálásához módosítsunk egy kicsit korábbi kulcsobjektumunkat:
nyilvános osztály MyKey {privát karakterlánc neve; private int id; public MyKey (int id, String name) {this.id = id; ez.név = név; } // standard getterek és beállítók @Orride public int hashCode () {System.out.println ("hashCode () hívása"); visszatérési azonosító; } // toString felülbírálása a szép naplózáshoz @Orride public boolean equals (Object obj) {System.out.println ("A kulcs meghívása: // létrehozott megvalósítás}}Figyelje meg, hogyan adjuk vissza egyszerűen a id attribútum hash-kódként - és így ütközésre kényszerül.
Ezenkívül vegye figyelembe, hogy a napló utasításokat felvettük a egyenlő és hash kód megvalósítások - hogy pontosan tudjuk, mikor hívják meg a logikát.
Most folytassuk az objektumok tárolását és visszakeresését, amelyek valamikor ütköznek:
@Test public void whenCallsEqualsOnCollision_thenCorrect () {HashMap map = new HashMap (); MyKey k1 = új MyKey (1, "firstKey"); MyKey k2 = new MyKey (2, "secondKey"); MyKey k3 = new MyKey (2, "harmadik kulcs"); System.out.println ("a k1 értékének tárolása"); map.put (k1, "firstValue"); System.out.println ("érték tárolása a k2 számára"); map.put (k2, "secondValue"); System.out.println ("érték tárolása a k3 számára"); map.put (k3, "harmadik érték"); System.out.println ("a k1 értékének lekérése"); String v1 = map.get (k1); System.out.println ("a k2 értékének lekérése"); Karakterlánc v2 = map.get (k2); System.out.println ("érték lekérése a k3 számára"); Karakterlánc v3 = map.get (k3); assertEquals ("firstValue", v1); assertEquals ("secondValue", v2); assertEquals ("harmadik érték", v3); }A fenti tesztben három különböző kulcsot hozunk létre - az egyiknek egyedi id a másik kettő pedig ugyanaz id. Mivel használjuk id mint a kezdeti hash érték, mindenképpen ütközés lesz az adatok tárolása és visszakeresése során ezekkel a kulcsokkal.
Ezenkívül a korábban látott ütközésmegoldási technikának köszönhetően elvárjuk, hogy minden tárolt értékünket helyesen kapjuk le, ezért az utolsó három sor állításai.
Amikor lefuttatjuk a tesztet, annak át kell mennie, jelezve, hogy az ütközések megoldódtak, és az elkészített naplózással megerősítjük, hogy az ütközések valóban történtek:
érték tárolása a k1 számára Hívás hashCode () érték tárolása k2 számára Hívás hashCode () érték tárolása k3 számára Hívás hashCode () Hívás egyenlő () kulcshoz: MyKey [név = secondKey, id = 2] érték lekérése a k1 számára Hívás hashCode () lekérés a k2 értéke hashCode hívása () érték lekérése a k3 számára hashCode hívása () A hívás egyenlő () a következő kulcshoz: MyKey [név = secondKey, id = 2]Vegye figyelembe, hogy a tárolási műveletek során k1 és k2 csak hash kód felhasználásával sikerült sikeresen feltérképezni az értékeikhez.
Azonban a k3 nem volt ilyen egyszerű, a rendszer észlelte, hogy a vödör helye már tartalmaz egy leképezést a k2. Ebből kifolyólag, egyenlő Összehasonlítást alkalmaztak megkülönböztetésükhöz, és létrehoztak egy összekapcsolt listát, amely mindkét leképezést tartalmazta.
Bármely más későbbi leképezés, amelynek kulcsa ugyanarra a gyűjtősávra vonatkozik, ugyanazt az útvonalat fogja követni, és végül a csatolt lista egyik csomópontjának helyébe lép, vagy felkerül a lista elejére, egyenlő Az összehasonlítás hamis értéket ad vissza az összes létező csomópontra.
Hasonlóképpen, a visszakeresés során k3 és k2 voltak egyenlő-hoz képest a helyes kulcsot, amelynek értékét be kell szerezni.
Végül, a Java 8-ból a csatolt listákat dinamikusan helyettesítik kiegyensúlyozott bináris keresési fákkal ütközési felbontásban, miután az ütközések száma egy adott vödör helyén meghaladja egy bizonyos küszöböt.
Ez a változás növeli a teljesítményt, mivel ütközés esetén a tárolás és a visszakeresés 2004-ben történik O (log n).
Ez a szakasz az nagyon gyakori a technikai interjúkban, különösen az alapvető tárolási és visszakeresési kérdések után.
7. Következtetés
Ebben a cikkben feltártuk HashMap Java megvalósítása Térkép felület.
A cikkben használt összes példa teljes forráskódja megtalálható a GitHub projektben.