Elasticsearch lekérdezések tavaszi adatokkal
1. Bemutatkozás
Egy korábbi cikkünkben bemutattuk, hogyan kell konfigurálni és használni a Spring Data Elasticsearch projektet. Ebben a cikkben megvizsgálunk az Elasticsearch által kínált többféle lekérdezési típust, és beszélünk a terepi elemzőkről és azoknak a keresési eredményekre gyakorolt hatásáról is.
2. Elemzők
Az összes tárolt karakterlánc mezőt alapértelmezés szerint egy elemző dolgozza fel. Az analizátor egy tokenizerből és több token szűrőből áll, és általában egy vagy több karakter szűrő előzi meg.
Az alapértelmezett elemző szétválasztja a karakterláncot közönséges szóelválasztókkal (például szóközökkel vagy írásjelekkel), és minden tokent kisbetűvé tesz. Ez figyelmen kívül hagyja az általános angol szavakat is.
Az Elasticsearch konfigurálható úgy is, hogy egy mezőt egyszerre elemzett és nem elemzettnek tekintsen.
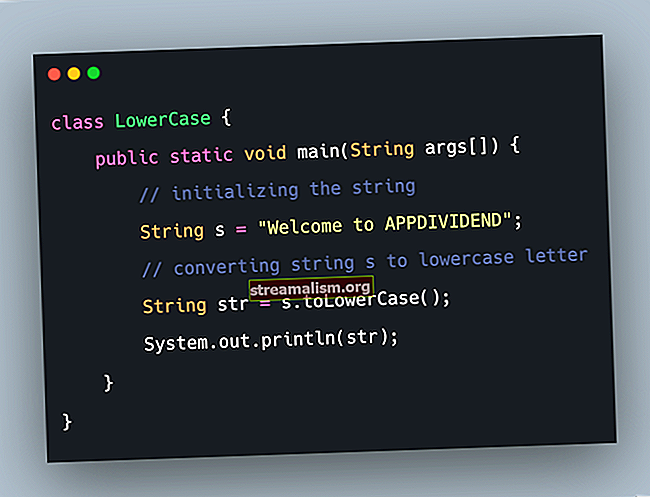
Például egy Cikk osztály, tegyük fel, hogy a cím mezőt standard elemzett mezőként tároljuk. Ugyanaz a mező az utótaggal szó szerint nem elemzett mezőként kerül tárolásra:
@MultiField (mainField = @Field (type = Text, fielddata = true), otherFields = {@InnerField (suffix = "verbatim", type = Keyword)}) private String title;Itt alkalmazzuk a @MultiField kommentár a Spring Data számára, hogy szeretnénk, ha ezt a mezőt többféle módon indexelnék. A fő mező a nevet fogja használni cím és a fent leírt szabályok szerint elemzik.
De adunk egy második jegyzetet is, @InnerField, amely leírja a cím terület. Használunk FieldType.keyword annak jelzése, hogy nem akarunk elemzőt használni a mező további indexálásakor, és ezt az értéket beágyazott mezővel kell kiegészíteni szó szerint.
2.1. Elemzett mezők
Nézzünk meg egy példát. Tegyük fel, hogy egy cikk a „Spring Data Elasticsearch” címmel szerepel az indexünkben. Az alapértelmezett analizátor felszakítja a karakterláncot a szóközöknél, és kisbetűs tokent állít elő:tavaszi“, “adat", és „rugalmas keresés“.
Most a kifejezések bármely kombinációját használhatjuk a dokumentumhoz:
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery (matchQuery ("title", "elasticsearch data")) .build ();2.2. Nem elemzett mezők
Egy nem elemzett mező nincs tokenezve, ezért csak egyezés vagy kifejezés lekérdezések használatakor egészében illeszthető:
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery (matchQuery ("title.verbatim", "Második cikk az Elasticsearchről")) .build ();Egyezési lekérdezéssel csak a teljes cím alapján kereshetünk, amely szintén különbséget tesz a kis- és nagybetűk között.
3. Match Query
A egyeztetési lekérdezés elfogadja a szöveget, a számokat és a dátumokat.
Három típusú „egyezés” lekérdezés létezik:
- logikai
- kifejezés és
- kifejezés_előtag
Ebben a szakaszban a logikai egyeztetési lekérdezés.
3.1. Találkozás logikai operátorokkal
logikai az egyezési lekérdezés alapértelmezett típusa; megadhatja, hogy melyik logikai operátort használja (vagy az alapértelmezett):
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery (matchQuery ("title", "Search engine"). Operator (Operator.AND)) .build (); SearchHits cikkek = elasticsearchTemplate () .search (searchQuery, Article.class, IndexCoordinates.of ("blog"));Ez a lekérdezés egy „Keresőmotorok” címet viselő cikket adna vissza, ha a kifejezésből két kifejezést megadna és operátor. De mi fog történni, ha az alapértelmezettel keresünk (vagy) operátor, ha csak az egyik kifejezés felel meg?
NativeSearchQuery searchQuery = új NativeSearchQueryBuilder () .withQuery (matchQuery ("title", "Engines Solutions")) .build (); SearchHits cikkek = elasticsearchTemplate () .search (searchQuery, Article.class, IndexCoordinates.of ("blog")); assertEquals (1, articles.getTotalHits ()); assertEquals ("Keresőmotorok", articles.getSearchHit (0) .getContent (). getTitle ());A "Kereső motorok”Cikk még mindig egyezik, de alacsonyabb pontszámot fog kapni, mert nem minden kifejezés egyezik.
Az egyes illeszkedő kifejezések pontszáma összeadódik az egyes kapott dokumentumok összesített pontszámával.
Előfordulhatnak olyan helyzetek, amikor a lekérdezésbe beírt ritka kifejezést tartalmazó dokumentum magasabb rangú lesz, mint egy olyan dokumentum, amely több általános kifejezést tartalmaz.
3.2. Homályosság
Amikor a felhasználó elgépelést végez egy szóban, akkor is meg lehet egyezni a kereséssel az a megadásával homályosság paraméter, amely lehetővé teszi a pontos egyezést.
Karakterlánc mezők esetén homályosság a szerkesztési távolságot jelenti: az egy karakterből álló változtatások száma, amelyeket el kell végezni egy karakterláncon, hogy azonos legyen egy másik karakterlánccal.
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery (matchQuery ("title", "spring date elasticsearch") .operator (Operator.AND) .fuzziness (Fuzziness.ONE) .prefixLength (3)) .build ();A előtag_hossz paramétert használják a teljesítmény javítására. Ebben az esetben megköveteljük, hogy az első három karakter pontosan egyezzen, ami csökkenti a lehetséges kombinációk számát.
5. Fráziskeresés
A fáziskeresés szigorúbb, bár a tócsa paraméter. Ez a paraméter megmondja a kifejezés lekérdezésnek, hogy milyen távolságra lehetnek egymástól a kifejezések, miközben a dokumentum egyezésnek tekinthető.
Más szóval, ez azt jelenti, hogy hányszor kell áthelyeznie egy kifejezést a lekérdezés és a dokumentum egyezéséhez:
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery (matchPhraseQuery ("title", "spring elasticsearch"). Slop (1)) .build ();Itt a lekérdezés illeszkedik a dokumentumhoz a címmelTavaszi adatok elasztikus keresése”, Mert a lejtőt egyre állítottuk.
6. Több mérkőzés lekérdezése
Ha több mezőben szeretne keresni, használhatja QueryBuilders # multiMatchQuery () ahol megadja az összes egyezendő mezőt:
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery (multiMatchQuery ("tutorial") .field ("title") .field ("tags") .type (MultiMatchQueryBuilder.Type.BEST_FIELDS)) .build ();Itt keresünk a cím és címkék mezők egy meccshez.
Vegye figyelembe, hogy itt a „legjobb mezők” pontozási stratégiát alkalmazzuk. A mezők között a pontszám maximális lesz, mint dokumentum pontszám.
7. Összesítések
Miénkben Cikk osztályban definiáltuk a címkék mező, amelyet nem elemeznek. Könnyen létrehozhatunk címkefelhőt összesítés használatával.
Ne feledje, hogy mivel a mezőt nem elemezték, a címkék nem lesznek tokenek:
TermsAggregationBuilder aggregation = AggregationBuilders.terms ("top_tags") .field ("tags") .order (Terms.Order.count (false)); SearchSourceBuilder builder = new SearchSourceBuilder (). Összesítés (összesítés); SearchRequest searchRequest = új SearchRequest (). Indexek ("blog"). Típusok ("cikk"). Forrás (készítő); SearchResponse response = client.search (searchRequest, RequestOptions.DEFAULT); Térkép eredmények = response.getAggregations (). AsMap (); StringTerms topTags = (StringTerms) results.get ("top_tags"); Lista kulcsok = topTags.getBuckets () .stream () .map (b -> b.getKeyAsString ()) .collect (toList ()); assertEquals (asList ("elasticsearch", "rugós adatok", "keresőmotorok", "bemutató"), kulcsok);8. Összefoglalás
Ebben a cikkben megvitattuk az elemzett és a nem elemzett mezők közötti különbséget, valamint azt, hogy ez a megkülönböztetés hogyan befolyásolja a keresést.
Ismerkedtünk az Elasticsearch által biztosított többféle lekérdezéssel is, például az egyezési lekérdezéssel, a kifejezésegyezés lekérdezésével, a teljes szöveges kereséssel és a logikai lekérdezéssel.
Az Elasticsearch számos más típusú lekérdezést kínál, például földrajzi, szkript és összetett lekérdezéseket. Elolvashatja őket az Elasticsearch dokumentációjában, és felfedezheti a Spring Data Elasticsearch API-t, hogy ezeket a lekérdezéseket felhasználhassa a kódban.
A cikkben használt példákat tartalmazó projekt a GitHub tárházban található.